strona główna  ARTYKUŁY Elektronika Wykorzystanie systemu wieloprocesorowego w kryptografii symetrycznej w układzie FPGA
ARTYKUŁY Elektronika Wykorzystanie systemu wieloprocesorowego w kryptografii symetrycznej w układzie FPGA
|
|
15 lipiec 2010


 |

|

|

|






|
|

Zaprezentowano algorytm przygotowania systemu wieloprocesorowego oparty na procesach programowych (softcore) PicoBlaze i MicroBlaze, przeznaczony do wykonywania blokowych algorytmów kryptograficznych. Szczególna uwaga została zwrócona na sposób komunikacji między procesorami. Dokonano weryfikacji, porównania złożoności logicznej oraz wymaganego czasu na stworzenie zaprezentowanych systemów. Zaproponowane rozwiązania wykorzystane zostało do realizacji obliczeń zorganizowanych w potok, które rozbite na elementarne podprogramy wykonywane były przez poszczególne procesory. Przedstawiona została zmodyfikowana architektura mikroprocesora PicoBlaze umożliwiająca ustalenie rozmiaru pamięci programu, RAM oraz stosu.
Obecnie dostępne układy programowalne dysponują w obrębie pojedynczego układu scalonego dużą liczbą zasobów logicznych umożliwiając w ten sposób zwiększanie integracji projektowanego systemu, co wiąże się z obniżeniem kosztów i skróceniem czasu realizacji projektu. Zaistniała możliwość implementacji w ramach jednej struktury programowalnej więcej niż jednego programowego mikroprocesora, co sprzyja dalszej integracji złożonego projektu.
W artykule zaprezentowany został algorytm przygotowania systemu wieloprocesorowego w oparciu o procesory programowe (softcore) PicoBlaze i MicroBlaze, przeznaczony do wykonywania blokowych algorytmów kryptograficznych. Szczególna uwaga została zwrócona na sposób komunikacji między procesorami. Dokonano weryfikacji, porównania złożoności logicznej oraz wymaganego czasu na stworzenie zaprezentowanych systemów. Zaproponowane rozwiązania wykorzystane zostało do realizacji obliczeń zorganizowanych w potok, które rozbite na elementarne podprogramy wykonywane były przez poszczególne procesory. Przedstawiona została zmodyfikowana architektura mikroprocesora PicoBlaze umożliwiająca ustalenie rozmiaru pamięci programu,RAM oraz stosu.
W artykule przedstawiono: podstawowe założenia budowy systemu wieloprocesorowego i określone wymagania stawiane tego typu rozwiązaniom, sposób implementacji oraz wpływ przyjętych parametrów na liczbę wykorzystywanych zasobów logicznych, wyniki zaproponowanych pomiarów i ich omówienie oraz wnioski.
Realizacja systemu wieloprocesorowego w układzie programowalnym może być zorganizowana w następujący sposób:
Systemy autonomiczne pracują niezależnie od siebie, mogą być taktowane różnymi zegarami i wykorzystują różne zasoby. Nie wymagamy, aby systemy posiadały mechanizmy komunikacji wzajemnej do realizacji postawionych im zadań.
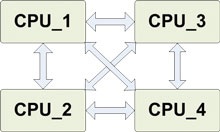
W przypadku kiedy rdzenie współpracują ze sobą wskazane jest zminimalizowanie liczby wymaganych połączeń w celu uniknięcia nadmiarowości pochłaniającej dodatkowe zasoby. Należy dostosować liczbę połączeń do realizowanego zadania przez system. Dla sieci niezupełnych pojawić może się konieczność zastosowania metod routingu i przekazywania pakietów do konkretnych procesorów. Routing zrealizowany może być sprzętowo poprzez dekodowanie adresu przez układ kombinacyjny, który zestawia odpowiednią ścieżkę lub programowo, gdzie każdy pakiet jest analizowany przez program, który decyduje o ewentualnym przekazaniu dalej pakietu. W tym przypadku przenosi się mechanizmy znane z układów NoC (Network on Chip) realizowanych w technologii ASIC do układów FPGA. Szczególną postacią jest struktura szeregowa, która umożliwia realizację algorytmów z wykorzystaniem potoku. Taka forma została przyjęta do realizacji postawionych celów. Na rysunku 1 przedstawione zostały wybrane architektury systemów wieloprocesorowych.
 a) a) | 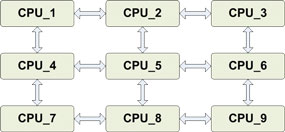 b) b) |
 c) c) | |
Rys. 1. Wybrane sposoby realizacji połączeń między procesorami: a) struktura zupełna (każdy z każdym), b) sieć kratowa, c) struktura szeregowa | |
W celu komunikacji między procesorami wykorzystuje się jeden z dwóch mechanizmów, tj.: pamięć dwuportową RAM, która umożliwia jednakowy dostęp do zawartości pamięci oraz pamięć o organizacji typu FIFO (First In First Out). Pierwsze rozwiązanie obsługuje wymianę danych poprzez określoną przestrzeń adresową. Zaletą tej metody jest swobodny dostęp do dowolnej komórki pamięci. Zasadniczą wadą jest konieczność uzyskania potwierdzenia czy można nadpisać dane w niej zapamiętane umieszczone pod konkretnym adresem. Wymusza to stosowanie semaforów, które po ustawieniu blokują zapis do określonych obszarów pamięci współdzielonej. Stosowana jest najczęściej w sytuacjach, kiedy potrzebny jest dostęp swobodny do dowolnej komórki pamięci. Kolejka FIFO wymaga pojedynczego adresu w przestrzeni adresowej, dzięki czemu operacja zapisu/odczytu przebiega szybciej (nie ma potrzeby zmieniania adresu docelowego/źródłowego). Podstawowymi wadami jest brak dostępu do dowolnej komórki, konieczne jest odczytanie wcześniej zapisanych danych, oraz jednokierunkowość transmisji, co wiąże się z koniecznością podwajania liczby wymaganych zasobów w celu wzajemnej komunikacji.
Informacja o aktualizacji zawartości pamięci przekazana jest przez rejestr statusu zawierający bit ustawiany przez układ piszący do pamięci po zakończeniu procedury zapisu, kasowany przez adresata po odczytaniu danych. Do nadzoru wymiany danych między układami zastosować można jeden z dwóch mechanizmów. Pierwszy wykorzystuje wejście przerwania mikroprocesora i zapewnia minimalizację opóźnień odczytu zwalniając tym samym zajęty obszar pamięci. Wymaga on bloku sterującego przerwaniami oraz ich automatyczne kasowanie. Druga metoda polega na cyklicznym sprawdzaniu rejestru statusu (informacji o rodzaju zawartości, ważności). Zaletą wykorzystania przerwań jest przyspieszenie wymiany danych między procesorami, wiąże się to jednak z możliwością pojawienia się przestojów w wykonywaniu programu głównego. Cykliczny odczyt statusu wprowadza przestój w transmisji zmniejszając jej szybkość efektywną [1].
Realizacja przetwarzania potokowego
Jedną z wielu struktur połączeń jest system szeregowy trzech i więcej procesorów. Rozwiązanie takie można wykorzystać do potokowego przetwarzania sygnału poprzez przyporządkowanie każdemu procesorowi określonego fragmentu algorytmu. W ten sposób skracamy czas przetwarzania do wartości odpowiadającej najdłuższemu etapowi. Wadą rozwiązania jest ograniczenie na wykonywanie skoków w obrębie całego algorytmu. Jeżeli występują skoki powinny być one realizowane w obrębie etapu. Komunikacja między procesorami odbywa się w jednym kierunku, co wskazuje, że dobrym rozwiązaniem jest zastosowanie pamięci typu FIFO, które będą buforować dane między następującymi po sobie procesorami (etapami). Rozmiar pamięci powinien być dopasowany do wielkości bloku danych potrzebnych do realizacji kolejnego etapu.
Jedną z grup aplikacji, które umożliwiają przetwarzanie potokowe są algorytmy szyfrowania blokowego. Jednym z nich, obecnie uznanym za standard, jest AES [2]. W artykule wykonana została implementacja z kluczem o długości 128-bitów. Algorytm ten operuje na blokach danych o rozmiarze 16 bajtów. W pierwszym kroku następuje dodanie mod 2 bloku danych z blokiem klucza głównego, następnie jest dziewięć pełnych rund składających się z operacji podmiany bajtów SubBytes, przestawiania wierszy ShiftRows, mieszania kolumn MixColumns oraz sumy mod 2 z odpowiednim podkluczem. Ostatnia, dziesiąta runda pozbawiona jest operacji mieszania kolumn. Pojedyncza operacja może być etapem potoku. Cechują się one jednak dużym zróżnicowaniem ilości wymaganych obliczeń. Najbardziej złożone jest mieszanie kolumn wymagające mnożenia macierzy przez wektor. Z tej racji przyjęto jako etap jedną kompletną rundę.
Po sygnale resetu lub uruchomieniu systemu procesor przed przystąpieniem do jej realizacji sprawdza, jaką pozycję zajmuje w potoku (CPU_ID), aby określić, które operacje należy wykonać w odpowiadającej mu rundzie. Dzięki temu nie ma potrzeby tworzenia indywidualnych programów dla poszczególnych procesorów. Następnie oczekuje się na podanie klucza głównego, który jest rozszerzany przez kolejne stopnie w potoku. Kolejnym krokiem jest cykliczne czytanie kolejnych bloków danych do przetworzenia. Po zapełnieniu potoku system osiąga maksymalną przepustowość zależną od czasu realizacji pierwszego etapu, który jest najdłuższy (dwa razy dodawany jest klucz).
W postaci pseudokodu referencyjny algorytm szyfrujący można zapisać następująco:
Cipher(byte in[4*Nb], byte out[4*Nb], word w[Nb*(Nr+1)]) begin byte state[4,Nb] state = in AddRoundKey(state, w[0, Nb-1]) for round = 1 step 1 to Nr–1 SubBytes(state) ShiftRows(state) MixColumns(state) AddRoundKey(state,w[round*Nb,(round+1)*Nb-1]) end for SubBytes(state) ShiftRows(state) AddRoundKey(state,w[Nr*Nb, (Nr+1)*Nb-1]) out = state end
|
Zmodyfikowana postać dostosowana do przetwarzania w potoku ma następującą postać:
Cipher(byte in[4*Nb], byte out[4*Nb], word w[Nb*(Nr+1)]) begin byte state[4,Nb] state = in if (CPU_nb == 0) AddRoundKey(state, w[0,Nb-1]) SubBytes(state) ShiftRows(state) if (CPU_nb < 9) MixColumns(state) AddRoundKey(state, w[round*Nb,(round+1)*Nb-1]) out = state end |
W celu zmniejszenia liczby cykli zegarowych koniecznych do wywoływania funkcji i przekazywania argumentów, poszczególne operacje zdefiniowane zostały jako funkcje inline. Zastosowano również inne sprawdzone sposoby optymalizacji struktury programu dla wybranych architektur [2, 3, 4] umożliwiające redukcję wymaganej liczby instrukcji oraz skoków do procedur.
Wymagania algorytmu na pamięć to 48 bajtów RAM dla przechowania danych i klucza oraz 256 bajtów ROM na potrzeby tablicy podstawień SBox/ISBox. Niewielkie wymagania umożliwiają wykorzystanie prostych procesorów 8-bitowych.
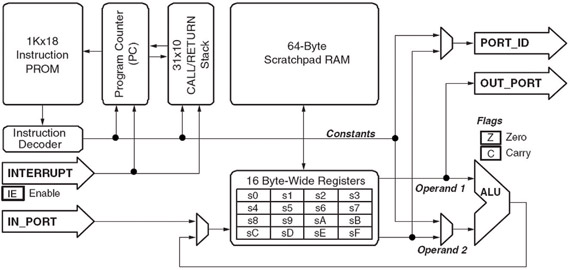
PicoBlaze (KCPSM3) [5] jest prostym 8-bitowym mikroprocesorem RISC, dostępnym w postaci plików źródłowych VHDL/ Verilog. Architektura mikroprocesora zawiera szesnaście 8-bitowych rejestrów ogólnego przeznaczenia, 64 bajty wbudowanej pamięci RAM, pamięć stosu o wielkości 32 pozycji. Wszystkie instrukcje są 18-bitowe i wykonywane w dwóch cyklach zegarowych. Wielkość programu jest stała i wynosi 1024 instrukcje. Procesor może obsłużyć do 256 bajtowych portów wejścia/wyjścia. W prosty sposób można przyłączać peryferia takie jak kontrolery pamięci, jednostki MAC (Multiply and Accumulate) i interfejsy komunikacyjne. Architektura procesora PicoBlaze została przedstawiona na rysunku 2.
Rys. 2. Schemat blokowy mikroprocesora PicoBlaze [5]
Dostarczony opis procesora w języku VHDL został wzbogacony o możliwość konfiguracji następujących parametrów:
Stworzony został opis pojedynczego etapu (stage). Składa się on z pamięci FIFO o rozmiarze 16 bajtów do komunikacji z kolejnym modułem, pamięci RAM o rozmiarze 256 bajtów do przechowywania tablicy SBox/ISBox, pamięci programu, procesora (64B RAM, wyłączona obsługa przerwań) oraz niezbędnej logiki do generowania sygnałów zapisu/odczytu. Wykorzystując syntezę warunkową wybiera się odpowiednią pamięć programu lub danych RAM oraz określa parametry procesora. Zaprojektowany został opis potoku (pipe), który umożliwia określenie liczby szeregowo połączonych etapów oraz ich parametry. Tak przygotowaną kolejkę, złożoną z dziesięciu procesorów, wykorzystano w projekcie głównym nazwanym MultiPicoBlaze(MPB), do której podłączono interfejs szeregowy RS232. Zawartość pamięci FIFO odczytywana jest po ukończeniu wysyłania aktualnie przetwarzanego bloku danych. W przypadku, kiedy kolejka jest pusta procesor cyklicznie sprawdza jej zawartość. Z racji zbliżonej złożoności obliczeń na poszczególnych etapach spowolnienie wynikające z cyklicznego sprawdzania są minimalne.
Konsekwencją wybrania takiego rozwiązania jest uproszczenie programu oraz umożliwienie oszacowania czasu wykonania danego etapu. Komunikacja odbywa się tylko w jednym kierunku ponieważ algorytm nie wymaga sprzężenia zwrotnego między poszczególnymi etapami.
Tworzenie projektu z wykorzystaniem środowiska ISE jest złożonym procesem wymagającym uwagi i sprawdzania projektu krok po kroku. Ułatwieniem procesu tworzenia systemu wieloprocesorowego w tym przypadku jest wykorzystanie syntezy warunkowej. Nie zwalnia to jednak projektanta z konieczności komentowania poszczególnych bloków kodu i określania ich przeznaczenia. Proces projektowania jest w wyniku tych dodatkowych zabiegów wydłużony, zyskuje się jednak na tym, że system jest bardziej dopasowany do realizowanych zadań. Rysunek 3 przedstawia uproszczony schemat blokowy zaproponowanego systemu.
Rys. 3. Schemat blokowy systemu MultiPicoBlaze
MicroBlaze [6] jest 32-bitowym soft procesorem zaprojektowanym pod kątem efektywnej implementacji w układach programowalnych firmy Xilinx. Posiada on architekturę typu RISC z big-endianową reprezentacją liczb. Dostępny jest wraz ze środowiskiem EDK (Embedded Development Kit) jako parametryzowana netlista. Za dodatkową opłatą można pozyskać procesor w postaci pliku źródłowego w języku VHDL.
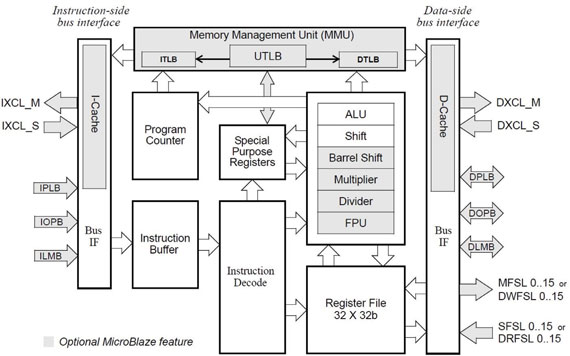
Wewnętrzną strukturę procesora MicroBlaze przedstawia rysunek 4. Elementy wyróżnione kolorem szarym są opcjonalne, konfigurowane przez użytkownika na etapie projektowania.
Rys. 4. Schemat blokowy soft mikroprocesora MicroBlaze [6]
Do elementów konfigurowalnych zaliczamy:
W środowisku EDK stworzony został projekt systemu składającego się z dziesięciu procesorów MicroBlaze, nazwany MultiMicroBlaze (MMB), z których każdy dysponuje 16kB pamięci na dane i instrukcje oraz został skonfigurowany z wyłączonymi wszystkimi opcjami rozszerzeń. Połączone były ze sobą poprzez moduły MailBox będące parą kolejek FIFO, każda mogąca pomieścić cztery słowa 32-bitowe, zapewniając w ten sposób komunikacje dwukierunkową. Moduł ten jest podłączony przez niebuforowaną magistralę Direct FSL (Fast Simplex Link) [7] do procesorów. Pierwszy i ostatni procesor wyposażone zostały również w magistralę PLB (Processor Local Bus), do której podłączone zostały kontrolery interfejsów szeregowych RS232. Zastosowano algorytm cyklicznego sprawdzania stanu kolejki z racji zbliżonej złożoności obliczeń na poszczególnych etapów, w konsekwencji powoduje to uproszczenie programu i umożliwia oszacowanie czasu wykonania danego etapu.
Tworzenie projektu w EDK jest uproszczone do poziomu wyznaczenia połączeń poszczególnych bloków, co w zdecydowanym stopniu przyspiesza proces tworzenia warstwy sprzętowej i ogranicza możliwości popełnienia błędów. Z procedurą tworzenia podstawowych rozwiązań wykorzystujących dwa procesory możemy zapoznać się w [8, 9]. Wprowadza ona jednak pewne ograniczenia w swobodzie konfigurowania. Niewątpliwą zaletą tego rozwiązania jest możliwość tworzenia aplikacji w języku C/C++.
Rysunek 5 przedstawia uproszczony schemat blokowy rozwiązania z procesorami MicroBlaze.
Rys. 5. Schemat blokowy systemu MultiMicroBlaze
W projektowaniu systemu wykorzystany został szereg narzędzi programistycznych. Pierwszym z nich jest ISE 10.1.3, przy użyciu którego zbudowano opis z wykorzystaniem języka VHDL, systemu opartego na mikroprocesorze PicoBlaze. Środowisko EDK 10.1.3 posłużyło do stworzenia systemu z procesorami MicroBlaze. Dodatkowo posiada ono moduł wspomagający tworzenie oprogramowania SDK (Software Development Kit), który posłużył do napisania aplikacji szyfrującej dane otrzymywane poprzez interfejs RS232. Program dla procesorów PicoBlaze powstał z użyciem środowiska pBlazeIDE 3.7.4, które poza kompilatorem asemblera, posiada rozbudowany debuger.
Rys. 6. Wykorzystana platforma testowa [10] |
W celu weryfikacji poprawności działania projektów w rzeczywistym systemie wykorzystane zostało
Testy przeprowadzono z użyciem płytki uruchomieniowej firmy AVNET AES-V5FXT-EVL30-G, zbudowanej na układzie FPGA Virtex 5 FX 30T firmy Xilinx (rys. 6.) Do układu doprowadzono sygnał zegarowy z oscylatora o częstotliwości 100 MHz. Płyta wyposażona jest w dwa interfejsy szeregowe (jeden z konwerterem USB – RS232), które posłużyły do transmisji przetwarzanych danych.narzędzie ChipScope Pro, które rejestruje przebiegi wewnątrz układu w czasie pracy umożliwiając w ten sposób określenie szybkości przetwarzania.
W tabeli 1. umieszczone zostało zestawienie liczby wymaganych zasobów przez dwie zaproponowane konfigurację oraz ich procentowy udział w odniesieniu do dostępnych w wykorzystywanym układzie FPGA.
Tabela 1: Zestawienie liczby wymaganych zasobów przez zaproponowane konfiguracje
| Rodzaj zasobów | MultiMicroBlaze | MultiPicoBlaze | Dostępne zasoby | ||
| Liczba | Udział | Liczba | Udział | ||
| Flip-Flop | 3282 | 16% | 808 | 4% | 20480 |
| LUT | 7017 | 34% | 1123 | 5% | 20480 |
| FPGA slice | 2224 | 43% | 475 | 9% | 5120 |
| BlokRAM | 40 | 59% | 5 | 7% | 68 |
System oparty na procesorach MicroBlaze wykorzystuje cztery razy więcej zasobów logicznych, co jest zasadne z uwagi na 32-bitową jednostkę ALU w odniesieniu do 8-bitowej w procesorze PicoBlaze. Wykorzystanie pamięci jest ośmiokrotnie większe, nie jest możliwe zmniejszenie obszaru pamięci ze względu na to, że minimum wymagane dla jednego procesora wynosi ok. 10 kB. Dla systemu z procesorem PicoBlaze jest to 2560 B dla każdego procesora. Prostsza architektura umożliwia również taktowanie systemu MultiPicoBlaze z zegarem 200 MHz wytworzonym z wykorzystaniem dostępnej pętli PLL, w przeciwieństwie do 100 MHz dla architektury z procesorami MicroBlaze. Rysunek 7 pozwala na porównanie wielkości systemów w obrębie układu FPGA.
 a) a) |  b) b) |
| Rys. 7. Rozplanowanie sieci połączeń w obrębie układu FPGA; a) MultiPicoBlaze, b) MultiMicroBlaze | |
Weryfikacja eksperymentalna zaproponowanych rozwiązań
Tabela 2 prezentuje wyniki uzyskane dla zaproponowanych konfiguracji. Zauważalna jest niewielka przewaga rozwiązania wykorzystującego procesor 32-bitowy, jednak duże wymagania dotyczące liczby zasobów czynią to rozwiązanie mniej ekonomicznym i pobierającym więcej energii od tego wykorzystującego architekturę 8-bitową.
Tabela 2 Zestawienie wydajności podczas szyfrowania oraz opóźnienie zapełnienia potoku
| Konfiguracja | Liczba cykli | Przepustowość Mb/s | Opóźnienie μs |
| MultiMicroBlaze @ 100MHz | 593 | 20,6 | 61,32 |
| MultiPicoBlaze @ 200MHz | 715 | 17,1 | 37,27 |
Tabela 3 przedstawia porównanie wydajności oraz liczby wymaganych zasobów z innymi znanymi rozwiązaniami jednoprocesorowymi.
Tabela 3 Porównanie wydajność szyfrowania dla innych rozwiązań z soft procesorami
| Konfiguracja | Przepustowość Mb/s | Liczba bloków slice |
| MultiPicoBlaze @ 200MHz | 17,07 | 475 |
| MultiMicroBlaze @ 100MHz | 20,59 | 2224 |
| MicroBlaze @ 50MHz [11] | 0,9 | 1385 |
| LEON @ 50MHz [12] | 9,10 | 2428 |
| ASIP @ 72,3MHz [13] | 2,18 | 122 |
| PicoBlaze @ 90MHz [13] | 0,71 | 119 |
Uzyskanie tak dobrych wyników możliwe było dzięki zastosowaniu nowoczesnego układu programowalnego Virtex 5 [14]; w stosunku do innych rozwiązań uzyskujemy w ten sposób lepsze wykorzystanie zasobów logicznych, mniejsze zużycie energii, większą elastyczność oraz możliwość pracy przy wyższych częstotliwościach.
W artykule zaprezentowano wyniki badań nad implementacją systemu złożonego z programowych mikroprocesorów PicoBlaze oraz MicroBlaze w układzie FPGA Virtex 5FXT. Podano opis oraz określono funkcjonalność takiego rozwiązania. Projekt został opracowany i zweryfikowany eksperymentalnie w Zakładzie Techniki Cyfrowej Instytutu Telekomunikacji WAT.
Zaproponowane rozwiązania to kolejny krok w prowadzonych pracach w zakresie implementacji w ramach jednego układu programowalnego kilku procesorów. Porównano otrzymane wyniki z innymi znanymi rozwiązaniami. Wyróżniają się one pozytywnie na tle konkurencyjnych propozycji zarówno pod względem wydajności jak i wymaganej liczby zasobów. Kluczową kwestią dla tego typu rozwiązań na przyszłość jest określenie, czy dodawanie kolejnych jednostek wykonawczych pozwala uzyskać większą wydajność systemu i jakim kosztem. Inną drogą jest rozważenie możliwości stworzenia procesora konwergentnego przystosowanego do pracy w środowisku wieloprocesorowym.
Autorzy:
Paweł Dąbal, Ryszard Pełka
Wojskowa Akademia Techniczna, Wydział Elektroniki, Instytut Telekomunikacji
[1] Dąbal P., Pełka R.: Implementacja algorytmu szyfrującego AES-128 w układzie FPGA Spartan 3E z procesorami Pico- Blaze; PAK 2008, Sierpień 2008 [2] Daemen J., Rijmen V.: The Design of Rijndael, AES - The Advanced Encryption Standard, Springer-Verlag, 2002 [3] Rijmen V.: Effcient Implementation of the Rijndael S-box [4] Gladman B.: A Specification for Rijndael, the AES Algorithm; September 2003 [5] Xilinx Inc.: UG 129 - PicoBlaze 8-bit Embedded Microcontroller User Guide, June 2008 [6] Xilinx Inc.: UG 081 - MicroBlaze Processor Reference Guide, January 2008 [7] Xilinx Inc.: Fast Simplex Link (FSL) Bus (v2.11a) Data Sheet, July 2007 [8] Xilinx Inc.: WP 262 - Designing Multiprocessor Systems in Platform Studio, November 2007 [9] Xilinx Inc.: XAPP 996 - Dual Processor Reference Design Suite, October 2008 [10] Avnet Inc.: Xilinx® Virtex™-5 FXT Evaluation Kit User Guide, May 2008 [11] Gonzalez I., Gomez-Arribas F.J.: Ciphering algorithms in MicroBlaze- based embedded systems, IEE Proc.-Comput. Digit. Tech., Vol. 153, No. 2, March 2006, pp. 87-92 [12] Hodjat A., Verbauwhede I.: Interfacing a high speed crypto accelerator to an embedded CPU; Signals, Systems and Computers, 2004. Conference Record of the Thirty-Eighth Asilomar Conference on Volume 1, Issue , 7-10 Nov. 2004 Page(s): 488 - 492 Vol.1 [13] Good T., Benaissa M.: Very Small FPGA Application-Specific Instruction Processor for AES; Circuits and Systems I: Regular Papers, IEEE Transactions on Volume 53, Issue 7, July 2006 Page(s): 1477 – 1486 [14] Xilinx: DS 100 - Virtex-5 Family Overview; February 2009 |

| REKLAMA |
|
|

| REKLAMA |
|
|