|
|
 |

|

|

|
Energetyka, Automatyka przemysłowa, Elektrotechnika






|
|
|
|
|
|
|
Omówiono implementacje algorytmów FFT dla przypadku przetwarzania sygnałów radarowych w czasie rzeczywistym. Przedstawiono charakterystyki wybranych algorytmów FFT oraz typowe problemy ich stałoprzecinkowej realizacji. Przeanalizowano rozwiązania stosowane w celu zapobiegania nadmiarom. Przedstawiono wyniki badań wpływu parametrów transformaty na dokładność i dynamikę otrzymanego wyniku. Dla badanego typu sygnału określono optymalną postać planu skalowania.
Istota algorytmów FFT, złożoność obliczeniowa
Wyznaczanie widma sygnału dyskretnego x(n) jest operacją powszechnie wykonywaną w systemach cyfrowego przetwarzania sygnałów. Narzędziem pozwalającym na wykonanie tej operacji jest dyskretna transformata Fouriera (ang. DFT – Discrete Fourier Transform), której równania można zapisać w następującej postaci:
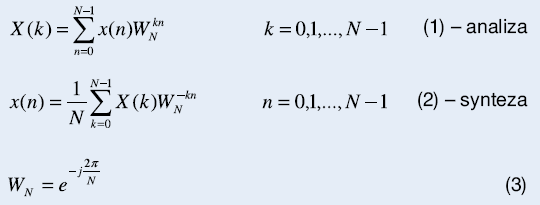
W ogólnym przypadku ciąg x(n) jest ciągiem zespolonym. Wyznaczenie DFT bezpośrednio z zależności (1) wymaga wykonania N2 mnożeń i N(N-1) sumowań liczb zespolonych.
Dla rozmiarów transformaty rzędu 1024-, 2048-punktów liczba operacji jest tak duża, że ten sposób wyznaczania widma jest nie realizowalny, szczególnie w aplikacjach czasu rzeczywistego z wysokimi wymaganiami czasowymi. Jest wiele różnych algorytmów FFT, ale wspólną cechą wszystkich jest znacznie mniejsza złożoność obliczeniowa względem metody bezpośredniej. Pojęcie „złożoność obliczeniowa” oznacza tu liczbę operacji arytmetycznych niezbędnych do realizacji algorytmu. Nie obejmuje ona operacji związanych z organizacją obliczeń, nie informuje więc o pełnej czasochłonności obliczeń. W przypadku wykonywania FFT przez klasyczne mikroprocesory, szczególnie starszego typu, operacje związane z organizacją programu zajmowały pomijalnie krótki czas względem operacji arytmetycznych. Sytuacja zmienia się w przypadku implementacji FFT w układach FPGA, które każdą operacje wykonują w identycznym czasie. Szczególnego znaczenia nabiera więc dobór najbardziej efektywnego algorytmu, również pod względem łatwości programowania.

Dla 1024-punktowej transformaty metoda bezpośrednia wymaga 1024^2=1048576 operacji arytmetycznych, zaś 2•(512)^2=524288. Liczba koniecznych do wykonania operacji arytmetycznych spada o połowę w stosunku do metody bezpośredniej. Zysk ten jest jednak zmniejszany poprzez występowanie operacji łączenia widm. Rekursywne dokonywanie podziałów i obliczanie krótszych DFT prowadzi do uzyskania dwupunktowych DFT i znacznej redukcji złożoności obliczeniowej. Końcowy schemat organizacji obliczeń wynikający z rekursywnych podziałów DFT pokazano na rysunku 1a.
Klasyfikacja algorytmów FFT [15,16]
Klasyfikacji algorytmów FFT można dokonać ze względu na kilka własności. Głównym kryterium podziału jest długość ciągu wejściowego N. Wyróżnia się algorytmy Cooley’a – Tuckey’a i algorytmy „Prime Factor”. Pierwsza grupa to algorytmy, dla których rozmiar transformaty jest całkowitą potęgą liczby 2, tzn. N=2M. Druga obejmuje algorytmy, gdzie rozmiar transformaty nie jest potęgą liczby 2 i da się przedstawić jako iloczyn liczb pierwszych. Klasyfikację algorytmów można również przeprowadzić ze względu na podstawę (ang. radix) podziału. Otrzymuje się wtedy algorytmy o podstawie 2 (radix-2), o podstawie 4 (radix-4), o podstawie 8 (radix-8), itd. Algorytmy można sklasyfikować również ze względu na dziedzinę podziału, wyróżnia się wtedy algorytmy z podziałem w czasie DIT (ang. Decimation In Time) oraz z podziałem w częstotliwości DIF (ang. Decimation In Frequency).
Charakterystyka algorytmów FFT
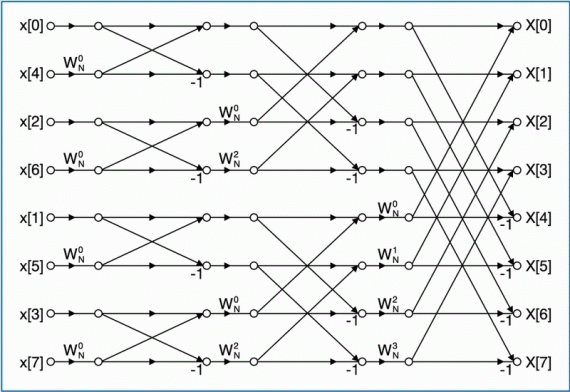
Wspomniany rekursywny podział obliczeń, w przypadku Radix-2, prowadzi do schematu obliczeń, takiego jak na rysunku 1a. Dla większej podstawy podziału powstają bardziej złożone schematy. Każdy algorytm wykonywany jest w określonej liczbie etapów: M=logPN, gdzie p jest podstawą algorytmu. Elementarna operacja algorytmu określana jest jako operacja motylkowa. Algorytmy FFT zmieniają uporządkowanie danych wyjściowych względem danych wejściowych: radix-2 wprowadza tzw. bit reverse w indeksie próbek, a radix- 4 digit reverse.
Radix-2 z podziałem w czasie DIT [12]
Algorytm radix-2 z podziałem czasowym powstaje z przekształcenia równania dyskretnej transformaty Fouriera (1) do
postaci zawierającej sumę dwóch transformat:
• pierwszej, obliczonej dla parzyście indeksowanych elementów wejściowej sekwencji danych (parzystych próbek sygnału wejściowego),
• drugiej, dla nieparzystych próbek sygnału wejściowego.
Przekształcone w ten sposób równanie przedstawiono poniżej.
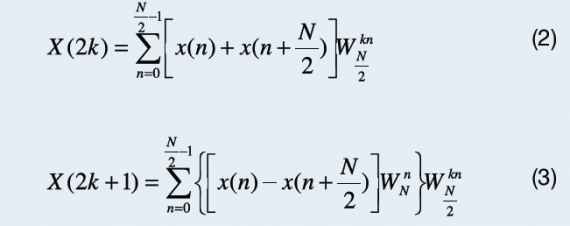
Graficzny schemat obliczeń reprezentujący powyższe równania dla N=8 pokazano na rysunku 2a.
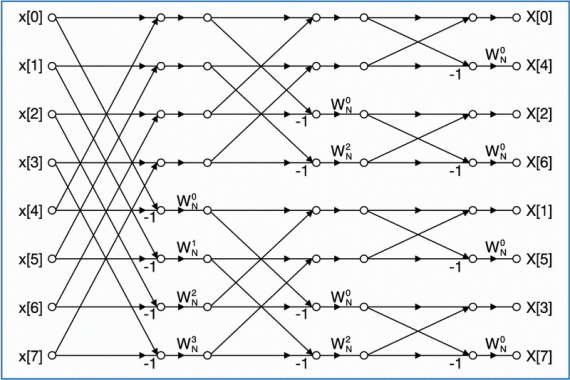
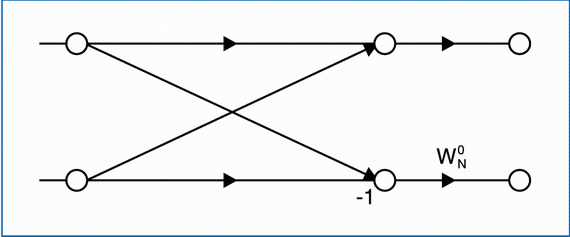
Dane wejściowe (rys. 2) są uporządkowane w naturalnej kolejności a dane wyjściowe w odwrotnej kolejności bitów w indeksie. Pojedyncza operacja motylkowa (rys. 2b), jest podobna do operacji motylkowej algorytmu z podziałem w czasie (rys. 1b). Obejmuje ona dwa sumowania liczb zespolonych i jedno mnożenie. Liczba etapów określona jest wyrażeniem M=log2N, na każdym etapie wykonuje się N/2 operacje motylkowe. Całkowita złożoność obliczeniowa
wynosi: Nlog2N sumowań oraz (N/2)log2N mnożeń liczb zespolonych.
Korekcja formatu wyników operacji arytmetycznych
Wynikiem stałoprzecinkowych operacji arytmetycznych są liczby o długości większej niż dane wejściowe. Wynik mnożenia jest sumą długości czynników mnożenia, np.: mnożenie p-bitowej próbki i b-bitowego współczynnika, generuje wynik o długości p+b bitów. Z uwagi na ograniczoną długość słowa stosuje się korekcję długości wyniku, zazwyczaj do wartości p. Korekcji można dokonać poprzez obcięcie lub zaokrąglenie mniej znaczących bitów.
Wynik sumowania dwóch p-bitowych próbek nie wymaga korekcji, ale może przekroczyć maksymalną wartość dającą się zapisać na p bitach, tzn. może powstać nadmiar.
Wynik sumowania dwóch p-bitowych próbek nie wymaga korekcji, ale może przekroczyć maksymalną wartość dającą się zapisać na p bitach, tzn. może powstać nadmiar.
Wykonywanie korekcji wyników mnożenia wiąże się z wprowadzaniem błędu, który jest zależny:
• od sposobu wykonania korekcji,
• od wartości, jakie reprezentują sobą liczby stałoprzecinkowe: ułamki, liczby całkowite,
• od sposobu reprezentacji liczb ujemnych: uzupełnienie do dwóch, uzupełnienie do jedności, notacja znak-moduł.
Radix-4 [13]
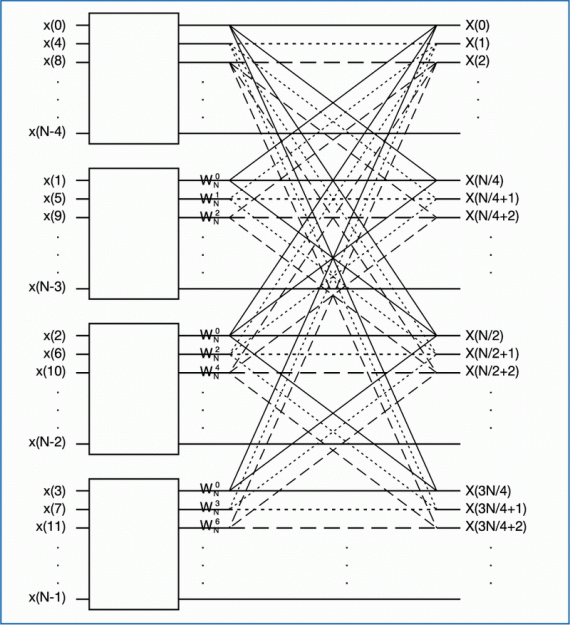
Algorytm radix-4 z podziałem czasowym powstaje z przekształcenia równania N-punktowej dyskretnej transformaty
Fouriera (1) do postaci zawierającej sumę czterech krótszych N/4-punktowych transformat. Podzbiory danych do
tych krótszych transformat są tworzone przez czterokrotne rozrzedzenie sekwencji próbek sygnału x(n), tj. rozrzedzenie sygnału w czasie. Tworzone są cztery podzbiory:
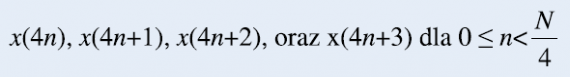
Aby powyższy podział był możliwy, parametr N określający liczbę próbek sygnału wejściowego musi być potęgą
liczby 4. Końcowe równanie algorytmu przedstawiono poniżej.
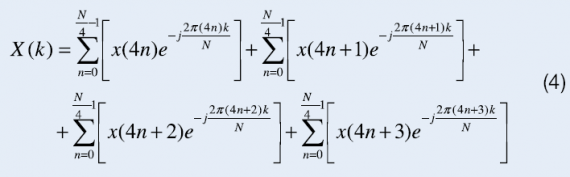
Graficzną ilustrację metody, na której opiera się algorytm radix-4 (4) przedstawiono na rysunku 3a. a operację motylkową tego algorytmu na rysunku 3b. Algorytm ten wymaga wykonania mniejszej liczby etapów, M=log4(N). Każdy etap to N/4 obliczenia motylkowe, charakteryzujące się trzema mnożeniami i ośmioma sumowaniami liczb zespolonych. Całkowita złożoność obliczeniowa wynosi (3N/8)log2(N) mnożeń i Nlog2N sumowań liczb zespolonych. Spadek liczby mnożeń w stosunku do algorytmu Radix-2 wynosi 25%.
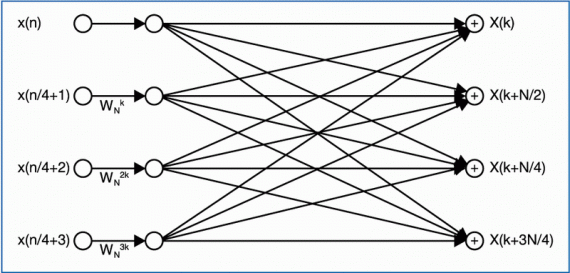
Algorytm Radix-4 z podziałem w częstotliwości charakteryzują się identyczną złożonością obliczeniową. Analogicznie
jak w przypadku algorytmów o podstawie 2, schemat operacji motylkowej dla podziału w częstotliwości jest podobny do
podziału w czasie. Mnożenie przez współczynnik obrotu występuje po operacji sumowania zespolonego.
Split-radix [14]
Algorytm ten łączy własności algorytmu o podstawie 2 i algorytmu o podstawie 4. Struktura takiego algorytmu jest nieregularna. Operacja motylkowa (rys. 4) przyjmuje kształt litery „L”. Nieregularna struktura może utrudnić implementację tego algorytmu w niektórych procesorach. Równanie (5) opisujące algorytm przedstawiono poniżej.
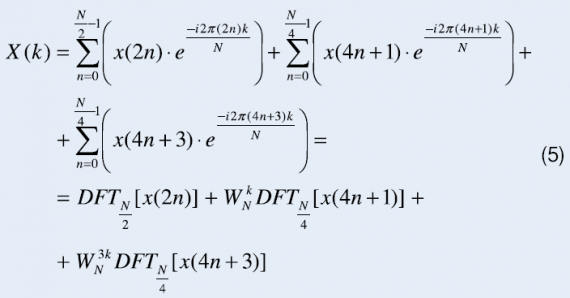
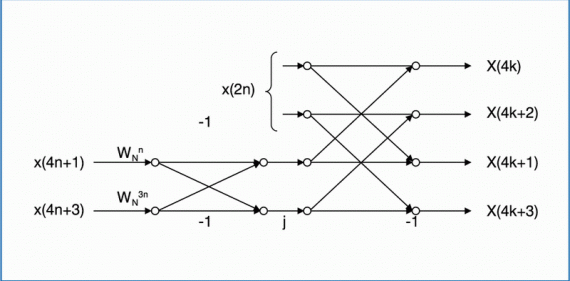
Złożoność obliczeniowa algorytmu wynosi: Nlog2(N) sumowań i (N/3)log2(N) mnożeń liczb zespolonych.
Wybór algorytmu do implementacji
Spośród omówionych algorytmów najbardziej efektywny ze względu na złożoność obliczeniową jest algorytm Radix-4,
ale jego przewaga nad Radix-2 jest niewielka. Oba algorytmy charakteryzują się regularną strukturą ułatwiającą programowanie. Radix-4 ustępuje jednak algorytmowi Radix-2 pod względem elastyczności parametru N oraz charakteryzuje się większą złożonością struktury. Z tych powodów do implementacji w FPGA wybrano algorytm Radix-2 DIF.
Problemy implementacji algorytmu Radix-2 DIF
Implementacja algorytmów FFT w układach FPGA stwarza dwa zasadnicze problemy:
• konieczność stosowania arytmetyki stałoprzecinkowej o ograniczonej długości słowa danych, w układach Virtex jest to 18 bitów,
• złożony i czasochłonny proces diagnostyki programu.
Zastosowanie arytmetyki stałoprzecinkowej powoduje dalsze problemy szczegółowe, tj.:
– możliwość wystąpienia nadmiarów w operacjach arytmetycznych,
– konieczność korekcji formatu słowa po operacjach arytmetycznych.
Metody zapobiegania nadmiarom
Występowanie nadmiarów prowadzi do zniekształcenia wyniku, konieczne jest więc zapobieganie ich powstawaniu.
Jest kilka metod zapobiegania nadmiarom, ale zastosowanie ich wiąże się z utratą dynamiki wyniku i wydłużeniem czasu wykonywania algorytmu lub wzrostem wymagań sprzętowych.
Możliwe jest użycie następujących metod.
• Pełna precyzja (ang. Full-precision unscaled arithmetic), polega ona na rozszerzeniu długości słowa danych o n+1
bitów, gdzie n jest liczbą etapów algorytmu. Wynika to z faktu, iż potencjalnie na każdym etapie może pojawić się
nadmiar. Zapewnia to propagację nadmiaru na starsze bity. Zastosowanie tej metody jest ograniczone możliwościami sprzętowymi.
• Blokowy zmienny przecinek (ang. Block floating-point), polega na wykonywaniu obliczeń transformaty aż do
momentu wystąpienia pierwszego nadmiaru w danym etapie. W takim przypadku wyniki bieżącego etapu są kasowane, następuje powrót do początku bieżącego etapu, skalowanie danych i ponowne obliczenia. Metoda nie nakłada wymogów na długość słowa danych, ale zmniejsza dynamikę wyników proporcjonalnie do liczby skalowań. Każdorazowe wystąpienie nadmiaru powoduje zwiększenie czasu wykonywania algorytmu.
• Skalowanie (ang. Scaled fixed-point), metoda bezwarunkowego skalowania danych przed każdym etapem
obliczeń; polega na podzieleniu danych wejściowych etapu przed jego rozpoczęciem przez założoną wartość, np.: 2, 4,
8, itd. Dla FFT radix-2 będzie to najczęściej dzielenie przez 2 lub 4, a dla radix-4 przez 4 lub 8. Metoda może wprowadzać niepotrzebne dzielenia i zmniejszenie dynamiki wyniku, ale gwarantuje najszybsze wykonanie obliczeń.
Pierwsza metoda jest rzadko stosowana z uwagi na zwiększone zużycie zasobów sprzętowych struktury FPGA. Metoda skalowania danych wymaga zaprojektowania planu skalowania. Wiąże się to z określeniem struktury M-elementowego
wektora poprzez ustalenie liczby skalowań i jej rozkładu na poszczególnych etapach. Strukturę wektora przedstawić
można jako: [NM, …, N2, N1], np.: [1, …, 0, 2]. Elementy wektora wskazują liczbę skalowań na danym etapie a indeks
elementu wektora wskazuje numer etapu. Dla przykładowej struktury wektora element N1=2 oznacza konieczność dwukrotnego skalowania danych przed pierwszym etapem obliczeń (dwukrotne przesunięcie bitowe w prawo równoważne dzieleniu przez 4), a element N2=0 oznacza brak skalowania.
Zastosowanie blokowego zmiennego przecinka nie wymaga planu skalowania. Potrzeba skalowania jest wykrywana automatycznie po wykonaniu każdego kolejnego etapu obliczeń. W ten sposób powstaje optymalny plan skalowania, wiąże się to jednak ze znacznym wzrostem czasu wykonywania algorytmu.
Dobór planu skalowania
Od liczby skalowań zależy dynamika i dokładność otrzymanego wyniku. Metoda blokowego zmiennego przecinka
pozwala wprawdzie na określenie optymalnego planu skalowania, jednak stosowanie jej w systemach czasu
rzeczywistego, pracujących w systemach radiolokacyjnych jest niekorzystne z uwagi na możliwość wydłużenia czasu
wykonania algorytmu. Nadrzędnym zadaniem staje się więc określenie bezwzględnego planu skalowania, optymalnego
pod względem dynamiki i poprawności wyniku. Konieczna zatem jest estymacja przedziału, w którym będzie poszukiwana wartość liczby skalowań Sn. Wartości dopuszczalne
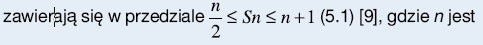
Diagnostyka programu
W układach FPGA czas cyklu diagnostycznego, tj.: przygotowanie programu, załadowanie do FPGA i sprawdzenie
działania jest dużo dłuższy niż w przypadku implementacji algorytmów w klasycznych procesorach. Brak możliwości pracy krokowej utrudnia diagnostykę występujących błędów.
Badania algorytmu
Występowanie przedstawionych problemów wymusza przeprowadzenie dokładnej analizy działania i weryfikacji algorytmu przed jego implementacją w strukturze FPGA. Z uwagi na trudności diagnostyki w środowisku docelowym konieczne staje się przeprowadzenie symulacji algorytmu w środowisku naśladującym działanie układu FPGA. Badania muszą być przeprowadzone dla wszystkich możliwych konfiguracji parametrów algorytmu, tj.: rozmiaru transformaty, długości słowa danych, planu skalowania, sposobu korekcji formatu wyników.
Treść i warunki badań
Badaniu poddano wpływ parametrów algorytmu na poprawność i dynamikę wyników. W celu wykonania badań opracowano program w języku C, w środowisku LabWindows/CVI5.5. Program umożliwiał przybliżenie warunków pracy układu FPGA w zakresie arytmetyki i długości słowa.
Własności programu:
• interfejs graficzny (rys. 5) pozwalający wybrać dowolną konfigurację parametrów,
• rozmiar transformaty: 1024, 2048, 4096 punktów,
• długość słowa danych: 1-14 bitów,
• wybór metody korekcji wyników,
• zliczanie nadmiarów na każdym etapie algorytmu,
• możliwość ustawienia dowolnego planu skalowania,
• możliwość porównania wyników z realizacją zmiennoprzecinkową,
• zapis wyników do pliku.
Do oceny jakościowej wyników otrzymanych w arytmetyce stałoprzecinkowej i porównania ich z realizacją zmiennoprzecinkową użyto następujących miar:
• unormowany współczynnik korelacji widm:

Miara (6) określa podobieństwo otrzymanego widma z realizacją zmiennoprzecinkową. Wartości bliższe jedności świadczą o większym podobieństwie wyniku stałoprzecinkowego do realizacji zmiennoprzecinkowej. Miara (7) charakteryzuje poziom składowej stałej względem maksymalnej wartości w otrzymanym widmie. W przypadku idealnym (brak składowej stałej) przyjmuje ona wartość -∞. Wartości bliższe -∞ wskazują na niższy poziom składowej stałej, a zatem na dokładniejszy wynik. Miara (8) określa stopień wykorzystania dostępnego rozmiaru słowa. Przy jej określaniu wykorzystano właściwość, iż wydłużenie słowa o 1 bit powoduje wzrost dynamiki maksymalnej wartości słowa o 6 dB.

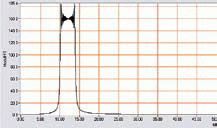
Do badań algorytmu użyto sygnału z liniową modulacją częstotliwości LFM o parametrach: fC=12 MHz, Δf=4 MHz, N=4096, ti=40,95 μs, fs=100 MHz. Sygnał wygenerowano symulacyjnie bez zakłóceń, w postaci liczb rzeczywistych z zakresu -1≤x≤1. Fragment postaci czasowej (ti=5,1 µs) przedstawiono na rysunku 6a, zaś na rysunku 6b – widmo sygnału.
Wyniki badań
Badanie wpływu rozmiaru transformaty i długości słowa danych
• Badania przeprowadzono dla trzech rozmiarów transformaty N=4096, N=2048, N=1024 punktów; dla trzech
długości słowa danych Q=12, Q=13, Q=14 bitów oraz współczynnika obrotu WN w formacie Q1.14. Zastosowano
zachowawczy plan skalowania z przesuwanym na kolejne etapy elementem „2”: [1, …, 1, 2], [1, …, 2, 1,], itd.
• Otrzymane charakterystyki współczynnika korelacji widm (rys. 7) i względnego poziomu składowej stałej (rys. 8)
przedstawiono w funkcji numeru etapu, na którym występowało skalowanie przez współczynnik „2”.
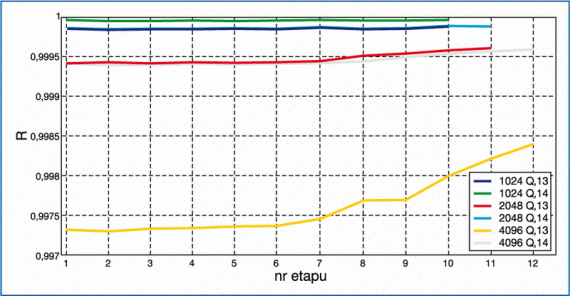
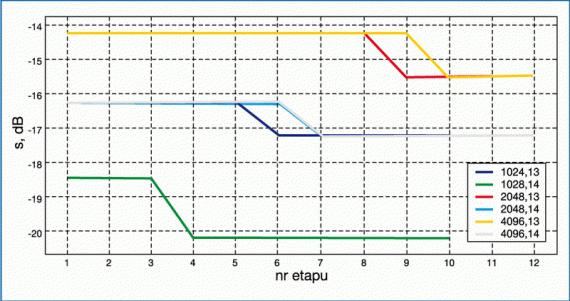
• Dla obu użytych miar jakości najlepsze wyniki uzyskuje się w przypadku tej samej pary parametrów algorytmu: N=1024
i Q=14 (ciemnozielona linia). Mniejszej liczbie etapów obliczeń M odpowiada mniejsza liczba operacji mogących powodować nadmiar wyników. Słowa o większej precyzji charakteryzują się mniejszą wartości kwantu, przez co
zmiany wynikające z korekcji formatu i skalowań danych są mniejsze. Zauważalny jest wzrost współczynnika korelacji
przy przesuwaniu elementu „2” w planie skalowania na późniejsze etapy. Otrzymane wyniki są zgodne z oczekiwaniami.
Badanie wpływu korekcji wyniku
• Otrzymane wyniki symulacji dla dwóch możliwych sposobów korekcji wyniku wskazały na wzrost wpływu sposobu korekcji wraz ze spadkiem długości słowa danych. Dla dłuższych formatów słowa wagi bitów pomijanych są małe w porównaniu do wag najstarszych bitów na których zapisany jest wynik.
Badanie wpływu liczby skalowań
Badania wpływu planu skalowania przeprowadzono zmniejszając liczbę skalowań występującą w wektorze zachowawczym. Dla każdej wartości Sn możliwe jest zaprojektowanie skończonej liczby planów skalowania.
• Z przeprowadzonych symulacji, dla badanego sygnału LFM, otrzymano optymalną liczę skalowań równą Sn=7.
Przy takiej liczbie skalowań otrzymano najkorzystniejsze wartości miar użytych do opisu jakościowego.
• Wybór liczby skalowań warunkuje poprawność oraz dokładność wyniku. Mała liczba skalowań może nie zapewnić
poprawności wyniku, zbyt duża powoduje wzrost poziomu składowej stałej oraz spadek dynamiki wyniku wywołany
większą liczbą skalowań.
Optymalny plan skalowania dla badanego sygnału
Wnioski z badań wskazywały na istnienie optymalnego planu skalowania dla badanego typu sygnału. Poszukiwanie optymalnej postaci wektora przypominało metodę blokowego zmiennego przecinka. Kolejne stosowane plany skalowania oraz wyniki uzyskane przy ich zastosowaniu przedstawiono w tabeli 1.
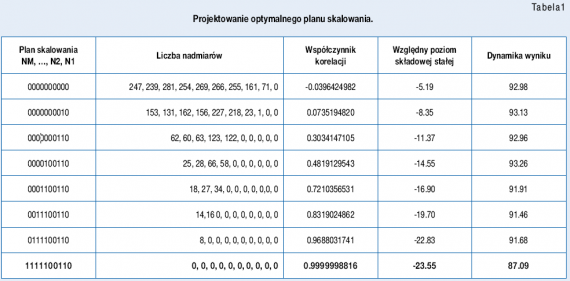
Rezultat otrzymany dla planu skalowania w postaci:
[1,1,1,1,1,0,0,1,1,0] charakteryzuje się największą wartością współczynnika korelacji, najniższym względnym poziomem
składowej stałej oraz dynamiką wyniku na dopuszczalnym poziomie. Uzyskany optymalny plan skalowania zapewnia
największą dokładność otrzymanego wyniku.
Wnioski
Przeprowadzone badania wykazały, że właściwy dobór parametrów transformaty ma istotny wpływ na jej wyniki.
Najważniejszy okazał się plan skalowania, który może powodować:
• całkowite zniekształcenie wyników gdy jest źle zaprojektowany
• ograniczenie dynamiki wyników jeśli jest zachowawczy.
Znalezienie optymalnego planu skalowania wymaga przeprowadzenie badań konkretnego typu sygnału na modelu symulacyjnym transformaty. Zastosowanie modelu postępowania polegającego na badaniach symulacyjnych układu przed jego implementacją w FPGA może być wykorzystane w odniesieniu do implementacji dowolnej złożonej procedury DSP w FPGA.
Literatura
[1] Oppenheim A.V., Schafer R.W.: Cyfrowe przetwarzanie sygnałów, WKŁ, Warszawa 1979
[2] Lyons R. G.: Wprowadzenie do cyfrowego przetwarzania sygnałów, WKŁ, Warszawa 2006
[3] Szabatin J.: Podstawy teorii sygnałów, WKŁ, Warszawa 2003
[4] Zieliński T.P.: Cyfrowe przetwarzanie sygnałów. Od teorii do zastosowań, WKŁ, Warszawa 2005
[5] „Fast Fourier Transform v4.1” specyfikacja IPCore, Xilinx ISE 9.2i
[6] “Fixed Point Arithmetic and Q Format” – http://cnx.org/content/m10919/latest/
[7] Knight W.R., Kaiser A.: “A simple fixed-point error bound for the fast Fourier Transform”, IEEE Xplore
[8] Elterich A., Stammler W.: “Error analysis and resulting structural improvements for fixed point FFTs”, IEEE Xplore
[9] Uzun I.S., Amira A., Bouridane A.: “FPGA implementations of fast Fourier transforms for real-time signal and image processing”, IEEE Xplore
[10] “Overview of Fast Fourier Transform (FFT) Algorithms” – http://cnx.org/content/m12026/latest/
[11] “Decimation-in-Frequency (DIF) Radix-2 FFT” – http://cnx.org/content/m12018/latest/
[12] “Decimation-in-Time (DIT) Radix-2 FFT” – http://cnx.org/content/m12016/latest/
[13] “Radix-4 FFT Algorithms” – http://cnx.org/content/m12027/latest/
[14] “Split-radix FFT Algorithms” – http://cnx.org/content/m12031/latest/
[15] “The Prime Factor Algorithm” – http://cnx.org/content/m12033/latest/
[16] “Power-of-two FFTs” – http://cnx.org/content/m12059/latest/
Robert Kędzierawski
Wojskowa Akademia Techniczna, Wydział Elektroniki

| REKLAMA |
|
|

| REKLAMA |
|
|

















